AI의 기록과 인류의 망각: 데이터 권력 시대의 지배 문화와 배상의 권리
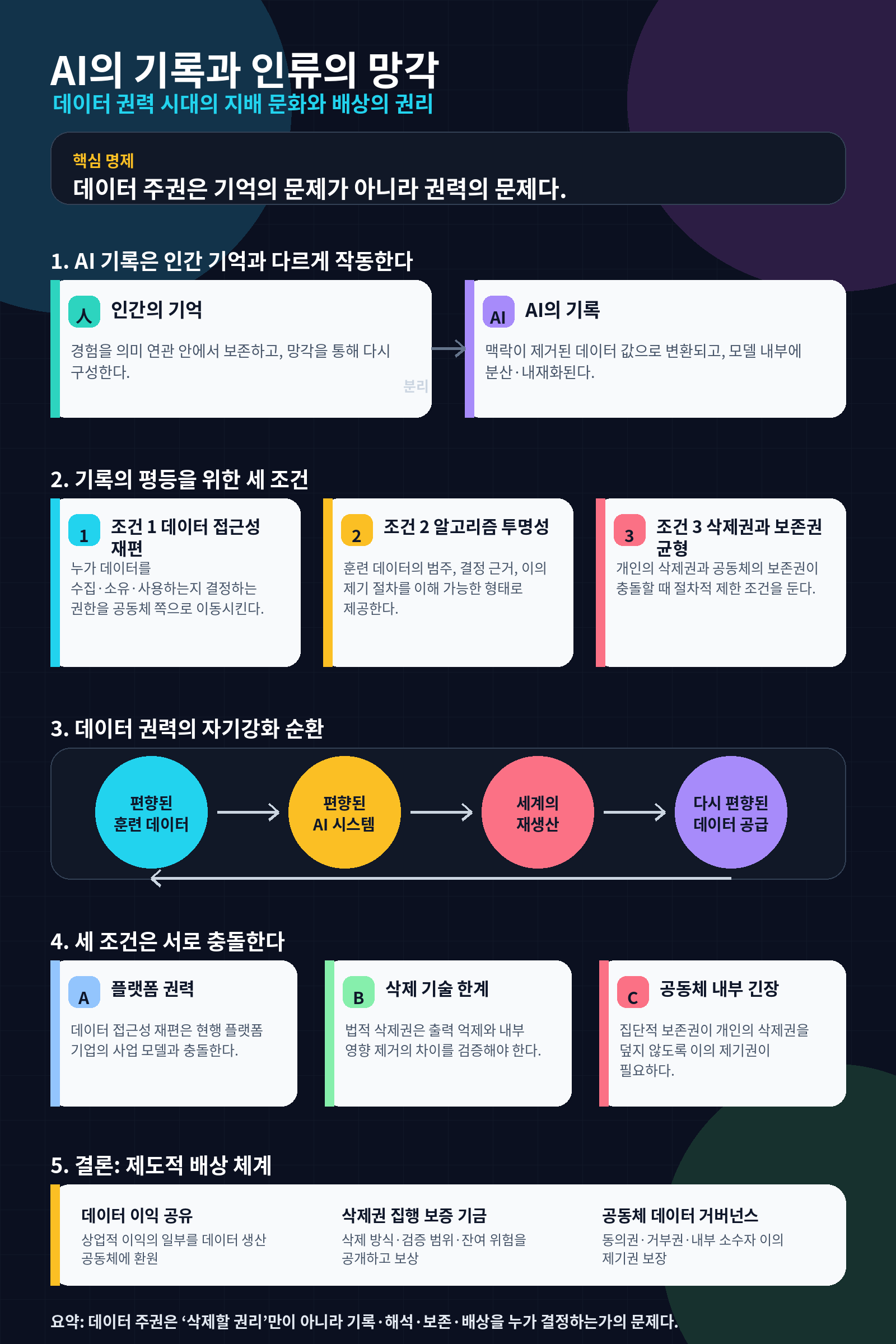
데이터 주권은 기억의 문제가 아니라 권력의 문제다. AI 시스템이 인류의 과거와 현재를 기록하는 인프라가 된 지금, 누가 기록되고 누가 삭제되며 누가 그 결정을 내리는가라는 물음은 정치경제적 물음이다. 기록의 평등이 성립하려면 세 조건이 동시에 충족되어야 한다. 데이터 접근성의 구조적 재편, 알고리즘 의사결정의 실질적 투명성, 삭제권과 보존권의 균형 있는 제도화가 그것이다. 세 조건 중 어느 하나가 결여되면 나머지 두 조건이 지배 문화의 자기 정당화 장치로 기능할 위험이 커진다. 이 글은 그 세 조건을 분석하고, 조건들 사이의 충돌 지점에서 제도적 배상 체계가 왜 필요한지를 논증한다.
'기록'과 '기억': 맥락이 소거된 데이터 값의 정치학
'기록'과 '기억'은 통상 같은 실재의 두 측면으로 이해된다. 기억은 주체가 경험을 의미 연관 안에서 보존하는 과정이고, 기록은 그 과정의 외부화된 흔적이다. 그러나 AI 시스템이 생산하는 기록은 이 연결을 끊는다. AI의 기록은 인간의 기억과 달리 맥락이 소거된 데이터 값이다. 어떤 개인의 진료 기록, 금융 거래 이력, 소셜미디어 발화 패턴은 해당 인간의 삶의 서사와 분리되어 수치와 벡터로 변환된다. 변환 과정에서 사라지는 것은 단순한 디테일이 아니라 그 데이터를 그 데이터로 만드는 맥락 자체다.
'망각'과 '삭제' 역시 같은 방식으로 분리된다. 인간의 망각은 능동적 과정이다. 트라우마 연구에서 확인되듯, 억압된 기억은 사라지지 않고 다른 형태로 지속된다. 망각은 재구성이며, 재구성은 주체가 살아있다는 증거다. 반면 데이터 삭제는 저장 매체에서 특정 값이 제거되는 기술적 절차다. 그러나 AI 시스템에서 '삭제'는 이 단순한 직관조차 만족하지 못한다. 대규모 언어 모델(LLM)의 경우, 특정 데이터의 영향은 모델 파라미터 전체에 분산·내재화되어 있기 때문에 해당 데이터를 데이터베이스에서 제거해도 모델이 그 정보를 '기억'하는 방식은 변하지 않는다.
2024년 12월 발표된 Cooper 외 연구자들의 논문은 이 문제를 정면으로 다룬다. 이들에 따르면 '기계 비학습(machine unlearning)'이라는 기술적 해법은 대부분 정보의 실질적 제거가 아니라 특정 출력의 억제를 수행하며, 두 목표는 근본적으로 다르다. 출력 억제는 특정 프롬프트에 대해 모델이 다르게 반응하도록 조정하는 것일 뿐, 모델이 해당 정보를 내부적으로 처리하는 방식을 변경하지 않는다(Cooper et al., "Machine Unlearning Doesn't Do What You Think," arXiv, 2024). 이 기술적 사실은 중요한 정치적 함의를 갖는다. 삭제권이 법적으로 보장되더라도, 현재 기술 수준에서는 출력 억제와 내부 영향 제거를 구분해 검증하기 어렵다. 따라서 삭제권의 집행은 단순한 처리 완료 통지가 아니라 삭제 방식, 검증 범위, 잔여 위험의 공개를 포함해야 한다. TechPolicy.Press(2025)는 이 문제를 "AI 시대에 잊힐 권리는 실질적으로 사망했다"는 표현으로 요약하고, HBS AI Institute(2025)는 기계 비학습이 데이터 제거의 신화에 가깝다는 점을 기술적으로 상세히 분석한다. 두 분석은 모두 삭제권의 법적 선언과 기술적 이행 사이의 간극이 구조적임을 확인한다.
EU GDPR 제17조는 '잊힐 권리(right to erasure)'를 법제화했다. 2024년까지 구글은 이 조항에 따른 개인정보 삭제 요청을 500만 건 이상 접수했다. 같은 해 캘리포니아주는 AI 시스템에 대한 개인정보 삭제권을 명시한 AB 1008을 입법 시도하며 AI 시대의 삭제권 공백을 메우려 했다. 그러나 기술적 공백은 법적 보장만으로 채워지지 않는다. 언어는 이해를 수정하는 장면을 마련하지만, 수정이 실제로 일어났는지는 그 언어 너머에서 확인되어야 한다. 법과 기술의 불일치가 이 지점에서 발생한다.
더 깊은 문제는 '상실'이라는 개념의 비대칭성이다. 지배 문화에 속한 집단의 데이터는 과잉 기록된다. 이들의 언어, 행동 패턴, 세계 해석 방식은 훈련 데이터의 다수를 구성하고, AI 시스템은 이 편향을 기준으로 정상성을 정의한다. 반면 주변화된 공동체의 데이터는 수집되지 않거나, 수집되더라도 이미 식민적 맥락에서 왜곡된 형태로 저장된다. 이 공동체들에게 '상실'은 삭제의 위협이 아니라 처음부터 기록되지 못한 존재의 문제다. 기록의 불평등은 기억의 불평등이며, 이 불평등은 AI 시스템이 세계를 재생산하는 방식 안에 구조화되어 있다.
조건 1: 데이터 접근성의 구조적 재편 — 누가 데이터를 소유하는가
기록의 평등이 성립하기 위한 첫 번째 조건은 데이터 접근성의 구조적 재편이다. 현재 데이터 생산과 수집 인프라는 소수의 플랫폼 기업에 집중되어 있다. 이 집중이 생산하는 효과는 단순한 시장 독점을 넘는다. 데이터를 대규모로 수집하고 처리할 능력을 가진 주체가 AI 훈련 데이터의 구성을 결정하고, 그 구성이 어떤 세계관이 정상으로 코드화되는지를 결정한다.
유엔 대학교(UNU)의 2024년 분석은 이 역학을 명확히 기술한다. 자원과 영향력을 가진 주체들이 대규모 데이터셋을 수집·관리·큐레이션하고, 이를 통해 자신들의 관점과 이익을 대표하는 AI 모델을 형성한다. 그 결과 주변화된 공동체들은 AI 훈련 데이터에서 과소대표되거나 오표현되며, 이렇게 형성된 AI 시스템은 기존 편향을 강화하고 구조적 불평등을 악화시킨다(Marwala, "The Dual Faces of Algorithmic Bias," UNU, 2024). 아프리카 AI 편향 사례를 분석한 Frontiers in Research Metrics and Analytics(2024)는 채용 알고리즘이 특권층 배경 지원자를 선호하고, 케냐 핀테크 영역에서 디지털 발자국이 적은 여성 이용자에게 불리한 신용 점수를 산출하는 구체적 사례를 제시한다. 훈련 데이터의 구성이 편향을 생산하고, 편향된 시스템이 세계를 재생산하며, 재생산된 세계가 다시 편향된 데이터를 공급하는 순환은 외부 개입 없이 자기 강화된다.
원주민 데이터 주권 운동(Indigenous Data Sovereignty movement)은 이 순환의 역사적 뿌리를 식민주의에서 찾는다. 식민 권력은 토지 수탈, 인구 통제, 문화 동화를 수행하기 위해 원주민 공동체에 대한 데이터를 수집했다. 이 데이터는 원주민 공동체의 관점에서 생산된 것이 아니라 식민 관료 체계의 분류 논리 안에서 구성되었다. 학자들은 이 구조가 디지털 시대에도 지속된다는 점을 '데이터 식민주의(data colonialism)'라는 개념으로 포착한다. 현대 AI 시스템은 동의나 혜택 없이 인간 경험을 디지털 자산으로 변환하는 자원 추출 체계로 기능한다(Peacehumanity.org, "Digital Sovereignty or Digital Colonialism," 2025). 원주민 데이터 주권은 개인의 프라이버시 보호가 아니라 집단적 자기결정권의 문제다.
2024년 미국에서는 Center for Tribal Digital Sovereignty가 설립되어 부족 정부들이 데이터 수집, 저장, 사용에 대한 권한을 이해하고 행사하도록 지원하기 시작했다. CARE 원칙(Collective Benefit, Authority to Control, Responsibility, Ethics)은 원주민 데이터 거버넌스의 실천적 프레임으로 확산 중이다. 그러나 이 움직임들은 기존 인프라의 외부에서 대안을 구축하는 전략을 택하며, 지배적 플랫폼 구조 자체를 변환하는 데까지 나아가지 못하고 있다.
데이터 접근성의 구조적 재편은 데이터 생산의 규칙을 설정하는 권한, 자신의 데이터가 어떻게 사용되는지 결정하는 권한, 자신에 대한 기록이 어떤 맥락에서 어떤 목적으로 저장되는지 통제하는 권한이 해당 공동체에 귀속되는 것을 의미한다. 접근성은 지배 구조의 재편 문제다.
조건 2: 알고리즘 투명성의 실질화 — 결정의 근거를 요구하는 권리
기록의 평등이 성립하기 위한 두 번째 조건은 알고리즘 의사결정의 실질적 투명성이다. 투명성 요구는 두 층위에서 작동해야 한다. 첫 번째 층위는 알고리즘이 어떤 훈련 데이터를 기반으로 작동하는지에 관한 것이고, 두 번째 층위는 특정 결정이 어떤 논리로 도출되었는지에 관한 것이다.
현재 대부분의 AI 시스템에서 두 층위 모두 블랙박스 상태다. 첫 번째 층위의 불투명성은 편향의 원천을 숨긴다. AI 시스템이 어떤 데이터로 훈련되었는지 외부에서 확인할 수 없다면, 그 시스템이 어떤 집단의 세계 해석을 정상으로 코드화하는지도 확인할 수 없다. 두 번째 층위의 불투명성은 이의 제기를 불가능하게 만든다. 대출 심사, 의료 진단, 채용 결정에 AI가 개입할 때, 해당 결정이 왜 그렇게 내려졌는지 알 수 없다면 불복할 근거를 가질 수 없다.
GDPR의 '설명 요구권(right to explanation)'은 이 두 번째 층위를 부분적으로 다루지만, 이행 강제의 메커니즘이 약하고 기술적 구현의 수준이 법적 요구와 실질적으로 괴리되어 있다는 비판을 지속적으로 받는다. 삭제 요청이 거부될 때 그 이유를 통보받을 권리는 보장되어 있으나, 그 이유의 기술적 근거를 검증할 권리는 보장되지 않는다. 개인은 시스템의 결정에 이의를 제기할 수 있지만, 시스템의 작동 방식 자체에 이의를 제기할 수단은 없다.
Cooper 외(2024)가 지적하듯, AI의 불투명성은 심지어 개발자 자신도 모델이 데이터를 어떻게 처리하거나 '기억'하는지 완전히 설명하지 못한다는 점에서 이중적이다. 이 불투명성은 개인의 통제력을 약화시키고, 신원 도용, 평판 훼손, 프라이버시 침해의 위험을 증가시킨다. 설계 투명성을 요구하는 것은 시스템의 모든 내부 로직을 공개하라는 것이 아니다. 특정 결정에 영향을 미친 데이터의 범주, 그 데이터가 어떤 방식으로 가중치를 받았는지, 그 결정을 뒤집을 수 있는 절차가 무엇인지를 이해 가능한 형태로 제공할 것을 요구하는 것이다.
알고리즘 투명성의 실질화는 기술적 과제이기도 하지만 근본적으로는 권력 관계의 문제다. 투명성을 제공하면 이의 제기가 가능해지고, 이의 제기가 가능해지면 시스템 설계자의 책임이 증가한다. 투명성 요구에 대한 기업의 저항은 사업 비밀 보호나 기술적 복잡성을 이유로 제시하지만, 실질적으로는 책임 회피의 구조를 유지하려는 동기와 분리되지 않는다. 알고리즘 투명성은 그 시스템에 의해 영향을 받는 사람들이 그 영향에 대한 설명을 요구할 수 있는 권리다.
조건 3: 삭제권과 보존권의 균형 — 망각의 비대칭성
기록의 평등이 성립하기 위한 세 번째 조건은 삭제권과 보존권의 균형 있는 제도화다. 이 조건은 앞선 두 조건보다 더 복잡한 긴장을 내포한다. 삭제와 보존은 서로 다른 공동체에게 서로 다른 방향으로 위협이 된다.
지배 문화에 속한 개인들에게 주된 위협은 과잉 기록이다. 과거의 실수, 범죄 기록, 개인 정보가 영구적으로 검색 가능한 상태로 유지되는 것은 사회적 복귀와 자기 재정의를 가로막는다. GDPR의 잊힐 권리는 이 위협에 대응하는 제도적 장치다. 그러나 주변화된 공동체들에게 주된 위협은 반대 방향에서 온다. 역사적 폭력, 문화적 기억, 집단적 서사가 기록되지 않거나 삭제된다. 원주민 언어, 구술 전통, 지역 공동체의 경험은 디지털 인프라에 포착되지 않거나, 포착되더라도 지배적 분류 체계의 언어로 번역된 형태로만 존재한다.
두 위협의 비대칭성은 하나의 제도적 해법으로 해결될 수 없다. 개인의 삭제권과 공동체의 보존권은 충돌한다. 예를 들어, 원주민 공동체의 역사적 피해 사례를 기록한 데이터베이스에서 특정 개인의 데이터를 삭제하라는 요청은 집단적 기억을 훼손할 수 있다. 반대로, 공적 이익을 위한 기록 보존이라는 명분으로 개인의 삭제권을 제한하는 것은 그 '공적 이익'을 정의하는 권력이 누구에게 있느냐는 질문을 회피한다.
이 충돌을 다루기 위해서는 삭제권과 보존권이 단일한 개인주의적 프레임 안에 묶여서는 안 된다는 인식이 출발점이다. 원주민 데이터 주권 이론가들이 지적하듯, 데이터 주권은 집단적 거버넌스의 문제다. 어떤 데이터가 보존되어야 하고 어떤 데이터가 삭제되어야 하는지에 대한 결정권은 해당 데이터에 의해 가장 직접적으로 영향을 받는 공동체에 귀속되어야 한다.
그러나 공동체 거버넌스 권한의 강화는 그 자체로 새로운 긴장을 생성한다. 공동체 내부의 권력 차이가 처리되지 않으면, 집단적 결정권이 공동체 내 소수자나 이탈 구성원의 개인 삭제권을 덮는 도구가 될 수 있다. 어떤 공동체가 특정 구성원의 데이터를 집단 서사의 일부로 보존하기로 결정할 때, 그 구성원 개인이 삭제를 요청할 권리는 어디까지 유효한가. 공동체 거버넌스 기관에는 이 충돌을 조정하는 절차적 제한 조건이 설계 단계에서 내장되어야 한다.
비대칭성의 또 다른 차원은 삭제 기술 자체의 한계에서 온다. 기계 비학습(machine unlearning) 연구들은 LLM의 경우 완전한 데이터 제거가 기술적으로 현재 불가능하거나 극도로 비용이 크다는 점을 반복적으로 확인한다. 처음부터 다시 훈련하는 방식은 실질적인 삭제에 가장 근접하지만, 수주에서 수개월이 소요되고 수백만 달러의 비용이 든다. 근사적 비학습 방법들은 효율적이지만 완전한 제거를 보장하지 못한다. 이 기술적 현실은 삭제권이 집행 불가능한 권리로 머물 위험을 제도적으로 인식해야 한다는 것을 의미한다.
세 조건의 충돌 지점과 제도적 배상 체계
세 조건 사이의 충돌은 예외적 상황이 아니라 구조적 긴장이다. 데이터 접근성의 구조적 재편은 알고리즘 투명성의 확대를 전제하지만, 투명성은 현행 플랫폼 기업의 사업 모델과 충돌한다. 삭제권의 강화는 보존권과 충돌하며, 두 권리의 우선순위는 어떤 공동체의 이익을 기준으로 삼느냐에 따라 달라진다. 기술적 한계는 법적 권리의 실행 가능성을 제한하고, 이 제한은 기술 인프라를 소유한 주체에게 유리하게 작동한다.
이 구조적 긴장은 권리 보장 차원을 넘는 제도적 배상 체계를 요구한다. 필요한 것은 역사적으로 형성된 데이터 불평등에 대한 제도적 배상 체계다. 데이터 식민주의가 역사적 식민주의의 디지털 연장이라면, '배상(reparation)'의 논리는 데이터 문제에도 직접 적용된다. 그 구조에서 발생한 불이익은 배상의 대상이다.
제도적 배상 체계는 세 층위에서 구체화될 수 있다. 첫 번째는 데이터 이익 공유 의무화다. 특정 공동체의 데이터를 활용해 상업적 이익을 얻은 AI 시스템 개발자는 해당 공동체에 이익의 일정 비율을 환원해야 한다. 이는 아프리카, 남아시아, 원주민 공동체의 데이터가 글로벌 AI 모델 훈련에 무상으로 활용되고 있는 현실에 대한 구체적 시정 조치다. 청구권자는 해당 데이터의 생산 공동체이며, 이익 산정 기준과 환원 비율은 독립적인 제3자 감사 기관이 결정해야 한다. 두 번째는 삭제권 집행 보증 기금이다. 기술적 한계로 인해 삭제권이 실질적으로 집행되지 못할 경우, 시스템 운영자는 해당 개인 또는 공동체에 보상을 제공할 의무를 진다. 이 기금은 권리를 선언에 머물지 않게 하는 집행 메커니즘이다. 기금의 운용 주체는 시스템 운영자와 독립된 감독 기구여야 하며, 삭제 방식·검증 범위·잔여 위험에 대한 공개 보고가 집행의 전제 조건이 된다. 세 번째는 공동체 기반 데이터 거버넌스 기관의 법적 지위 부여다. 원주민 공동체 및 주변화된 집단이 자신의 데이터에 대한 거버넌스를 독립적으로 수행할 수 있는 기관을 법적으로 인정하고, 이 기관이 상업적 데이터 활용에 대한 동의권과 거부권을 행사할 수 있도록 해야 한다. 이 기관의 의사결정 절차에는 공동체 내부 소수자의 이의 제기권이 명시적으로 포함되어야 하며, 집단 결정이 개인 삭제권을 제한하는 경우 그 제한의 범위와 조건을 사전에 공개해야 한다.
세 조건이 동시에 충족되지 않을 때 배상 체계가 지배 문화의 자기 정당화 장치로 기능할 위험은 구조적이다. 데이터 이익 공유가 이루어지더라도 알고리즘이 불투명하면 그 이익이 어디서 발생했는지 추적할 수 없다. 삭제권이 법제화되더라도 기술적 집행이 보증되지 않으면 권리는 형식이 된다. 공동체 기반 거버넌스 기관이 법적 지위를 얻더라도 훈련 데이터의 구성에 실질적으로 개입할 수단이 없으면 그 지위는 상징에 머문다.
데이터 주권은 데이터가 생산되고, 처리되고, 해석되고, 삭제되는 과정에서 누가 결정을 내리며 그 결정이 누구의 이익을 위해 작동하는지를 묻는 권한의 문제다. 이 물음에 답하는 제도적 구조가 배상의 실질적 내용이다.
참고자료
- Cooper, A. F., Choquette-Choo, C. A., Bogen, M., Jagielski, M., et al. "Machine Unlearning Doesn't Do What You Think: Lessons for Generative AI Policy, Research, and Practice." arXiv, December 2024.
- European Union. General Data Protection Regulation (GDPR), Article 17: Right to Erasure. 2018.
- California Legislature. Assembly Bill 1008 (AB 1008). 2024.
- Marwala, Tshilidzi. "The Dual Faces of Algorithmic Bias — Avoidable and Unavoidable Discrimination." United Nations University, 2024.
- Carroll, S. R., Duarte, M. E., and Liboiron, M. "Indigenous Data Sovereignty is not simply about Indigenous individuals collecting data toward an imagined gain, but rather is also a form of Indigenous governance through data based in right relation." In Indigenous Environmental Data Justice, 2024.
- Global Indigenous Data Alliance (GIDA). "CARE Principles for Indigenous Data Governance." 2023.
- American Indian Policy Institute and National Congress of American Indians. Center for Tribal Digital Sovereignty. 2024.
- Xu, J., Wu, Z., Wang, C., and Jia, X. "Machine Unlearning: Solutions and Challenges." arXiv, 2023.
- TechPolicy.Press. "The Right to Be Forgotten Is Dead: Data Lives Forever in AI." 2025.
- Harvard Business School AI Institute. "The Myth of Machine Unlearning: The Complexities of AI Data Removal." 2025.
- Frontiers in Research Metrics and Analytics. "Navigating algorithm bias in AI: ensuring fairness and trust in Africa." 2024.
인포그래픽
작성일 : 2026년 5월 10일